REST (REpresentational State Transfer) is a set of rules that has become the standard for designing web APIs.
On this pageJump to a section
Understanding and implementing these rules is essential for building applications that enable seamless communication between different systems.
In this article, we will cover the six rules for designing REST APIs.
Rule 1: Client-Server Architecture
The first principle of REST is the client-server architecture.
This means that the client and server operate independently of each other.
The client is responsible for the user interface and user experience, while the server handles data processing and storage.
Separating these enables more straightforward scalability, flexibility, and maintainability.
Example:

Consider an e-commerce application with a web-based user interface (UI) and a backend server managing product data. The web UI (client) requests product information from the backend server and presents it to the user. The backend server (server) processes the request, retrieves the product data from the database, and returns it to the client. The client and server operate independently, allowing each to be updated or scaled without affecting the other.
Rule 2: Stateless
In a RESTful API, each request from the client to the server must contain all the necessary information for the server to process that request.
The server should not store any information about the client’s state between requests.
This approach is called statelessness.
Example

Imagine a client wants to view the details of a specific product. The client sends a GET request to the server, including the product’s unique identifier. The server processes the request, retrieves the product data, and sends it back to the client. The server does not store any information about the client’s previous requests or actions. If the client wants to update the product information, it must send a new request containing all the necessary data, including any changes to be made.
Rule 3: Cacheable
To improve performance, RESTful APIs can make use of caching.
Caching allows clients to store responses from the server locally, reducing the need to repeatedly request the same data.
This can significantly decrease the load on the server and improve the response times for clients.
Example
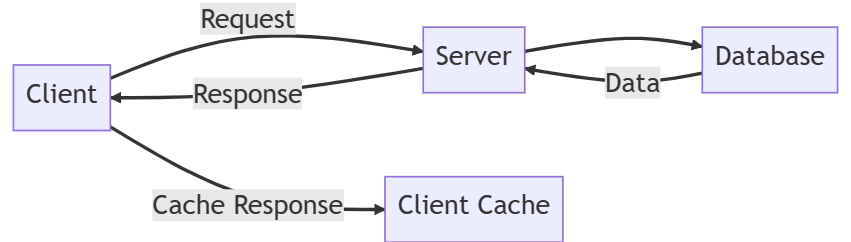
A client frequently requests a list of the top-selling products from an e-commerce server. The server can include cache control headers in its response, indicating how long the data should be considered fresh. The client can then store the response in its local cache and reuse it for subsequent requests, reducing the load on the server and improving the client’s response time.
Rule 4: Uniform Interface
One of the most critical principles of REST is the uniform interface.
It simplifies the communication between clients and servers by imposing a consistent set of constraints on API interactions.
The uniform interface allows different components to understand each other more easily, leading to better interoperability.
Example:
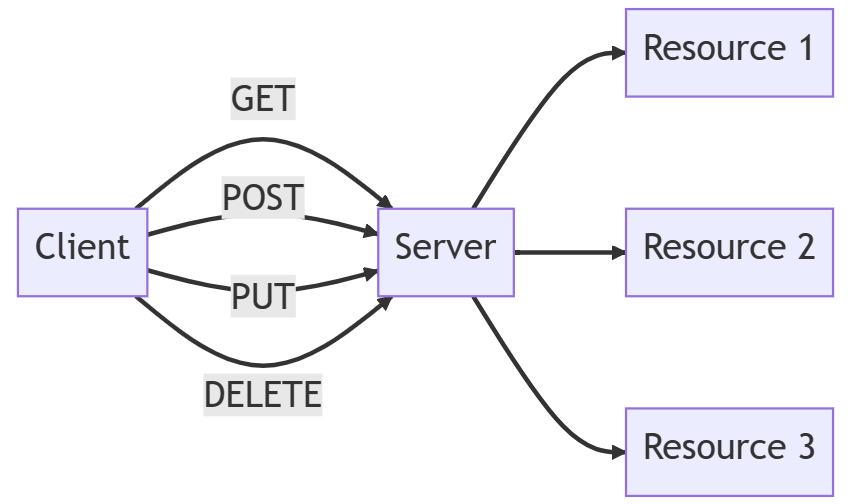
An e-commerce RESTful API may expose several resources, such as products, customers, and orders. The API uses a consistent naming convention for resource URIs (e.g., /products, /customers, /orders) and standard HTTP methods for resource manipulation (GET, POST, PUT, DELETE). This uniform interface makes it easier for clients to understand and interact with the API, as they can expect the same structure and behavior for all resources.
Constraints of Uniform Interface
The uniform interface has four main constraints:
- Resource identification:
Each resource must have a unique identifier, such as a URI.
Example: In an e-commerce API, a specific product might have the URI/products/123, where123is the product’s unique identifier. - Resource manipulation through representations:
Clients interact with resources through representations, like JSON or XML.
Example: A client retrieves a product’s information by sending a GET request to the product’s URI. The server responds with a JSON representation of the product, containing its properties and values. - Self-descriptive messages:
Each message must contain enough information to describe how to process the message.
Example: When a client sends a request to update a product, it includes the appropriate HTTP method (PUT), the resource URI, and a JSON representation of the updated product data. - Hypermedia as the engine of application state (HATEOAS):
Responses should contain links to related resources, allowing clients to navigate the API dynamically.
Example: When a client retrieves a product’s information, the server’s response might include links to related resources, such as the product’s category or manufacturer. The client can then follow these links to retrieve additional information without having to construct new URIs manually.
Rule 5: Layered System
REST APIs follow a layered system architecture, which means that each layer is only aware of the immediate layer it interacts with.
This separation of concerns allows for greater flexibility and maintainability, as individual components can be updated or replaced without affecting the entire system.
Example:

An e-commerce application can have multiple layers, such as a load balancer, an authentication layer, and a data processing layer. The load balancer distributes incoming requests to multiple servers, the authentication layer handles user authentication, and the data processing layer retrieves and manipulates data. Each layer communicates only with the adjacent layers, allowing changes or updates to one layer without impacting the others.
Rule 6: Code on Demand (optional)
Code on demand is an optional constraint of REST that allows the server to send executable code to the client when necessary.
This feature can enhance the client’s functionality without requiring a full application update.
However, it’s not a mandatory constraint for building RESTful APIs.
Example:
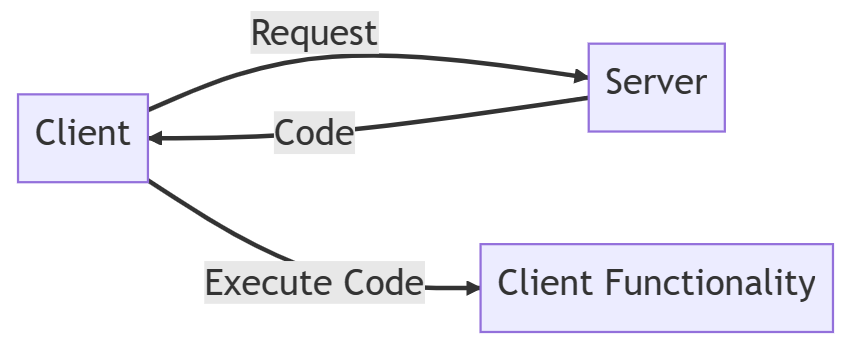
A web application may require additional client-side processing for a specific feature. Instead of embedding the code in the application, the server can send the required JavaScript code to the client on demand. This can reduce the overall size of the application and allow the server to update the code without requiring a client-side update.